This illustrated series was a collaboration between Julie and Allison, who like to talk endlessly about data, code, teaching, open science, and art. We’ve been collaborating since the beginnings of Openscapes: Allison created all artwork for the Openscapes website and slides and was part of the inaugural Champions cohort. Here, we wanted these illustrations to tell a story about why tidy data is so powerful for efficiency, repeatability, and collaboration, but also stand alone to be most flexible for teaching.
Please reuse & remix with your own communities, and enjoy:
- Download from https://github.com/allisonhorst/stats-illustrations
- Reuse/remix from this slide deck
- View/share this twitter thread
When we talk about organizing data to help us work in an efficient, reproducible, and collaborative way, we are talking about TIDY DATA. We mean deliberately thinking about the shape and structure of data – something that might not seem super exciting but is truly game-changing.
So let’s talk about what tidy data is and why it is so empowering for your analytical life.
What is tidy data?
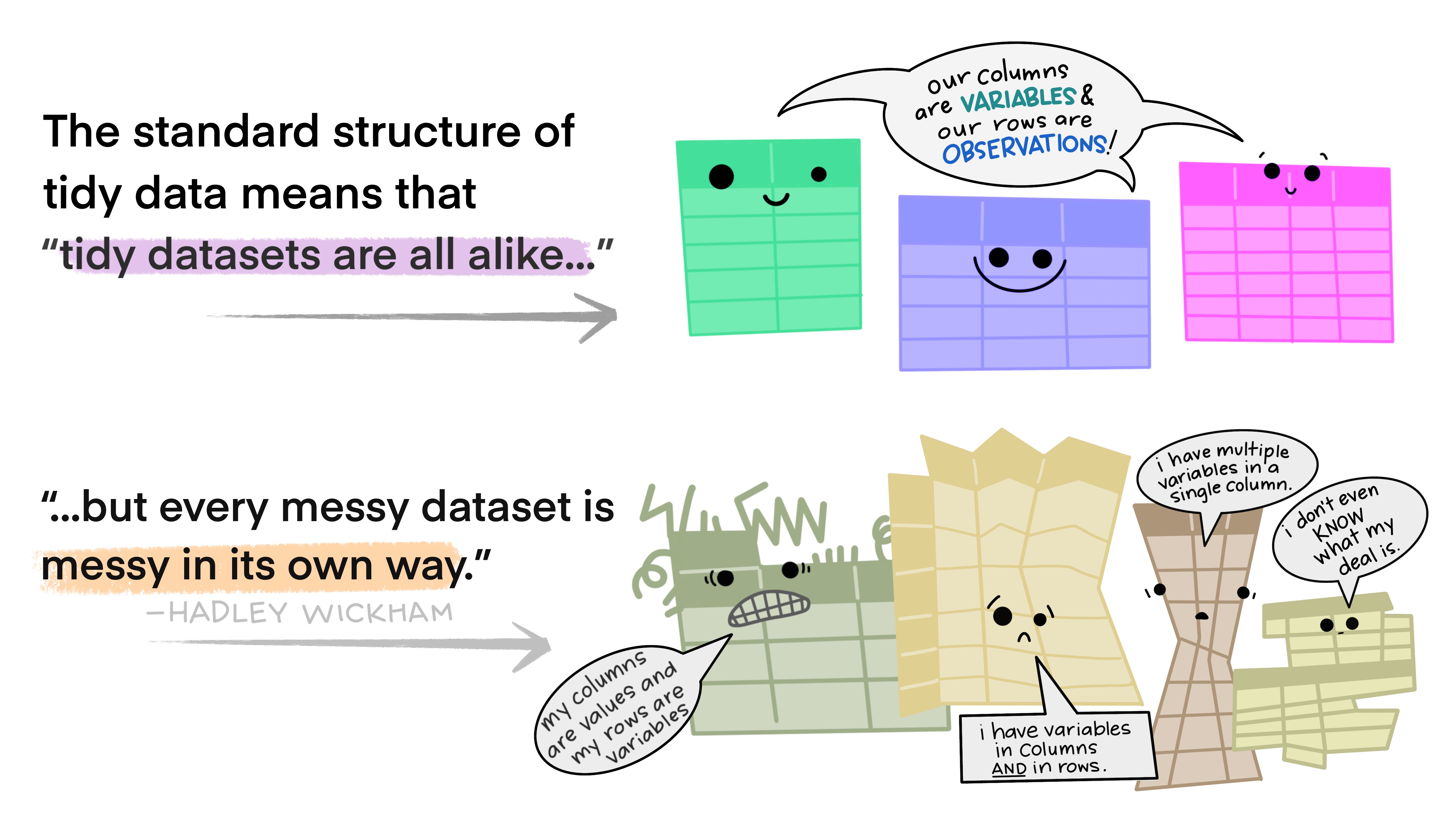
Tidy data is a way to describe data that’s organized with a particular structure – a rectangular structure, where each variable has its own column, and each observation has its own row (Wickham 2014).

This standard structure of tidy data led Hadley Wickham to describe it the way Leo Tolstoy describes families. Leo says “Happy families are all alike; every unhappy family is unhappy in its own way”. Similarly, Hadley says “tidy datasets are all alike, but every messy dataset is messy in its own way”.
Tidy data for more efficient data science
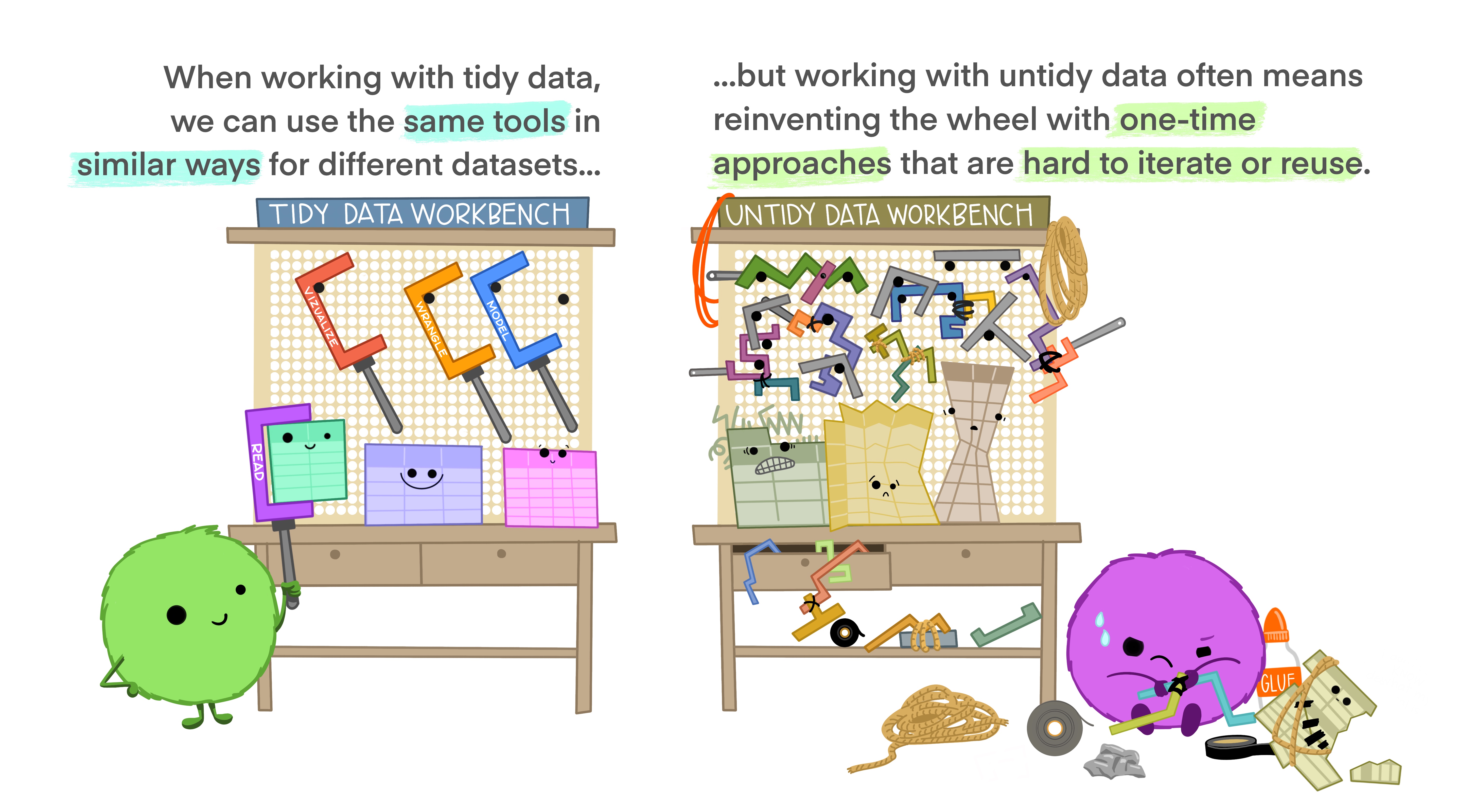
Tidy data allows you to be more efficient by using existing tools deliberately built to do the things you need to do, from subsetting portions of your data to plotting maps of your study area. Using existing tools saves you from building from scratch each time you work with a new dataset (which can be time-consuming and demoralizing). And luckily, there are a lot of tools specifically built to wrangle untidy data into tidy data (for example, in the tidyr package). By being more equipped to wrangle your data into a tidy format, you can get to your analyses faster to start answering the questions you’re asking.
Tidy data for easier collaboration
Tidy data makes it easier to collaborate because our friends can use the same tools in a familiar way. Whether thinking about collaborators as current teammates, your future self, or future teammates, organizing and sharing data in a consistent and predictable way means less adjustment, time, and effort for all.
Tidy data for reproducibility and reuse
Tidy data also makes it easier to reproduce analyses because they are easier to understand, update, and reuse. By using tools together that all expect tidy data as inputs, you can build and iterate really powerful workflows. And, when you have additional data entries, it’s no problem to re-run your code!
Tidy data for the win!
Once you are empowered with tools to work with tidy data generally, it opens up a whole new world of datasets that feel more approachable because you can work using familiar tools. This transferrable confidence and ability to collaborate might be the best thing about tidy data.

So for more efficient, reproducible, and collaborative analyses, make friends with tidy data!

Learn more about tidy data:
Wickham, H (2014). Tidy Data. Journal of Statistical Software 58 (10). jstatsoft.org/v59/i10/
“Informal and code-heavy version” of the full paper above: tidyr.tidyverse.org/articles/tidy-data
Broman, KW and KH Woo (2018). Data Organization in Spreadsheets. The American Statistician 72 (1). Available open access as a PeerJ preprint.
Grolemund, G & Wickham, H (2016). R for Data Science: Ch 12 (Tidy Data) https://r4ds.had.co.nz